

¿Por qué el bloqueo de hardware aceleró la supremacía del software? 🤔


🏛️ Editorial: La Paradoja de la Restricción
Esta semana hemos visto una lucha de poder por el dominio de la Inteligencia Artificial desde dos horizontes distintos. Si miras los titulares financieros recientes, verás a Occidente intentando resolver el problema de la IA lanzando montañas de dinero al fuego: TSMC anuncia un Capex de $56,000 millones de dólares, Nvidia absorbe a Groq para eliminar competencia arquitectónica, y OpenAI sigue pidiendo clusters de energía nuclear.
La estrategia occidental es clara: Fuerza Bruta. Ganar por volumen de cómputo.
Pero si miras la física de lo que ocurrió esta semana con DeepSeek-V3, verás una historia diferente. Un laboratorio chino, restringido por sanciones que le impiden acceder a los chips de punta (H100/B200), acaba de igualar el rendimiento de modelos que costaron $100M entrenar, gastando solo $5.6M.
¿Cómo? No con magia, sino con Ingeniería de la Escasez
Las sanciones no detuvieron el avance; simplemente hicieron que cambiarán de “fuerza bruta” a “eficiencia radical”. Al no tener acceso al ancho de banda masivo de los chips occidentales (H100), DeepSeek tuvo que optimizar para que la inteligencia cupiera en tuberías más estrechas:
FP8 (Entrenamiento Nativo en 8-bits): Mientras Silicon Valley lanza datos en precisión de 16-bits (BF16), DeepSeek forzó el entrenamiento en FP8. Esto no es solo un cambio de formato; reduce a la mitad el ancho de banda necesario para mover datos entre chips. Donde OpenAI necesita autopistas de información, DeepSeek optimizó la carga para que fluyera a velocidad máxima por carreteras secundarias.
MLA (Multi-Head Latent Attention): El cuello de botella actual de la IA es la memoria (VRAM), no el cómputo. MLA es una arquitectura que comprime drásticamente el caché KV (la “memoria de trabajo” del modelo). Esto permite manejar contextos masivos con mucho menos hardware, logrando que el rendimiento de inferencia sea económicamente viable donde otros modelos se ahogan en costos de RAM.
La lección para ti, como Creador Aumentado, es de soberanía:
La verdadera independencia tecnológica no es tener el hardware más potente (la GPU más cara o la MacBook más nueva). La soberanía real reside en la capacidad de diseño intelectual que hace que el hardware sea irrelevante.
Mientras Silicon Valley busca desesperadamente más poder de computo, la verdadera innovación se ha movido a los sótanos donde se optimiza el código. No busques más recursos; optimiza los que tienes hasta que sea la propia física la que te impida el avance.
🧠 Insight Maestro: Tu código es tu DeepSeek
La eficiencia extrema de este modelo nos enseña algo fundamental sobre cómo trabajamos hoy: El SaaS tradicional es la estrategia occidental (Fuerza Bruta), y tu código personalizado es la estrategia DeepSeek (Eficiencia Radical).
Hasta hoy, vivíamos aceptando la Deuda Técnica del Software Monolítico. Pagamos suscripciones mensuales ($29 USD) por herramientas genéricas, pesadas y llenas de funciones que no usamos. Es como alquilar un superordenador H100 para hacer una suma simple.
La caída en los costos de inferencia y la mejora en herramientas de codificación (Cursor/Claude) cambian esta ecuación de valor. La lección no es construye soluciones de precisión. En lugar de adaptar tu flujo de trabajo a un software gigante, ahora puedes generar un script de Python (”Micro-utilería”) que haga exactamente lo que necesitas y nada más.
El SaaS es un activo fijo, caro y rígido.
El Software generado por IA es un fluido: lo creas, lo usas para resolver el problema y, si el proceso cambia, lo desechas y generas uno nuevo.
🌀 Vibe-Shift: Esa es tu nueva soberanía. Dejar de ser un consumidor de bloatware para convertirte en un arquitecto de soluciones esbeltas, optimizadas hasta el átomo, tal como lo hizo DeepSeek. Si puedes describir el sistema con precisión lógica, puedes construirlo.
📡 Radar Estratégico
Lo que define los próximos 6 meses.
Mientras el mundo discute sobre chatbots, la infraestructura física y el mercado laboral están emitiendo señales inequívocas. Aquí están las tres coordenadas que debes vigilar esta semana:
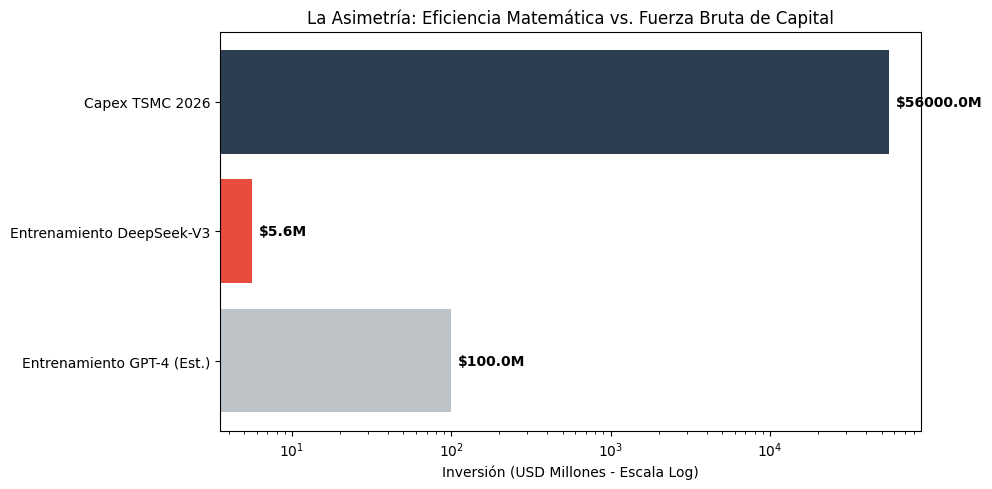
1. El Indicador Adelantado Definitivo: TSMC Capex ($56B) Taiwán acaba de comprometer $56,000 millones de dólares en gasto de capital para este año fiscal.
La Lectura: TSMC no invierte por fe, invierte sobre pedidos firmados. Esta cifra confirma que la demanda de hardware de IA no se desacelerará en los próximos 24 meses. La “burbuja” no va a estallar pronto; la infraestructura física apenas se está vertiendo.
Para dimensionar la apuesta de TSMC frente al costo de eficiencia de DeepSeek (La bifurcación del mercado):
2. Consolidación Hostil: Nvidia + Groq Los reportes confirman la adquisición de Groq por parte de Nvidia.
La Lectura: Groq y su arquitectura LPU (Language Processing Unit) eran la única amenaza real a la hegemonía de la GPU en inferencia pura. Nvidia no compró tecnología; compró la eliminación de una arquitectura rival. El ecosistema se cierra, lo que valida nuestra tesis editorial: la optimización de software (DeepSeek/SGLang) es tu única salida del monopolio de hardware.
3. La Rotación Laboral: Amazon vs. Microsoft Amazon anuncia despidos masivos para 2026 mientras Microsoft publica la lista de “40 roles más expuestos a la IA”.
La Lectura: No es una recesión, es una rotación de capital humano. Las empresas están liquidando roles de gestión intermedia (”Middle Management”) para liberar capital hacia infraestructura de cómputo y roles técnicos de supervisión de sistemas. Si tu trabajo es coordinar gente, estás en peligro. Si tu trabajo es orquestar sistemas (agentes), estás en alza.
🛠️ Stack Aumentado
Herramientas de grado industrial para tu arsenal personal.
Esta semana descartamos los juguetes y nos enfocamos en dos piezas de infraestructura que permiten la “Soberanía de Inferencia” que discutimos en el Editorial.
1. El Motor: SGLang (v0.4.2)
Qué es: Un framework de inferencia para LLMs diseñado para velocidad y control estructural.
Por qué te importa: Si vas a correr modelos locales o construir tu propio software, SGLang es superior a vLLM en casos complejos. Introduce RadixAttention, una técnica que reutiliza el caché KV (Key-Value) entre diferentes llamadas.
El Hack: Ideal para agentes que comparten un System Prompt largo y repetitivo. SGLang lo cachea automáticamente, reduciendo la latencia y el costo computacional drásticamente.
Instalación:
pip install sglang
2. El Supervisor: Microsoft Argos
Qué es: Un modelo de verificación para agentes multimodales.
Por qué te importa: El mayor problema del “Selfware” es que no sabes si tu agente está alucinando. Argos introduce un paradigma de “Reasoning-Action-Verification”. No solo ejecuta, sino que audita la ejecución antes de presentarte el resultado.
Uso: Integra Argos como una capa intermedia (middleware) en tus flujos de trabajo críticos para detectar errores de lógica antes de que rompan tu producción.
¿Ya estas construyendo tus propias aplicaciones?