



Esta semana en MondAI te conté que Meta lanzó los primeros miembros de su nueva familia de modelos: Llama 4 Scout y Llama 4 Maverick. Este lanzamiento, que ya contaba con al menos dos retrasos reportados y bastante especulación, se posicionó como una respuesta tanto a los modelos privados de OpenAI y Google, como a la creciente competencia de actores emergentes, notablemente el proveedor chino DeepSeek y sus modelos eficientes.
Los nuevos integrantes de la familia:
Llama 4 Scout (17B Activos / 109B Totales, 16 Expertos): Presentado como un modelo eficiente y el mejor multimodal de su clase, capaz de operar en una sola GPU Nvidia H100 (con cuantización Int4). Su característica estrella es una ventana de contexto masiva de 10 millones de tokens, un salto cuántico respecto a generaciones anteriores. Meta afirmó que supera a modelos como Gemma 3, Gemini 2.0 Flash-Lite y Mistral 3.1 en diversos benchmarks.
Llama 4 Maverick (17B Activos / 400B Totales, 128 Expertos): Descrito como el "caballo de batalla" para asistentes y chat, diseñado para ofrecer un rendimiento superior en relación costo-beneficio. Meta aseguró que supera a GPT-4o y Gemini 2.0 Flash en benchmarks clave y logra resultados comparables a DeepSeek v3 en razonamiento y código, pero con menos de la mitad de parámetros activos.
Además de los modelos lanzados, Meta dejó entrever la existencia de Llama 4 Behemoth, un monstruo entre los modelos aún en entrenamiento con 288 mil millones de parámetros activos y casi 2 billones de parámetros totales. Este gigante se utiliza para "destilar" conocimiento en Scout y Maverick y, según Meta, ya supera a modelos como GPT-4.5, Claude 3.7 Sonnet y Gemini 2.0 Pro en benchmarks STEM. Behemoth funciona tanto como base técnica como promesa de futuro dominio, manteniendo altas las expectativas. Mark Zuckerberg incluso afirmó no estar al tanto de que alguien estuviera entrenando un modelo más grande.

Esta aproximación revela una estrategia multi-nivelada. Meta no lanza un único modelo, sino una familia completa (incluyendo futuros modelos de "Razonamiento") dirigida a distintos casos de uso y capacidades de hardware. Al ofrecer opciones desde el eficiente Scout hasta el potente Maverick (y eventualmente Behemoth), Meta busca capturar un segmento de mercado más amplio, desde desarrolladores con recursos limitados hasta grandes empresas, aplicando una clásica estrategia de plataforma.
Futurinota 📝: La ambición de Meta es innegable, no solo quiere competir, quiere definir la próxima ola de IA "abierta" con modelos multimodales, eficientes y escalables. Las especificaciones sobre el papel son impresionantes, pero la verdadera prueba, como siempre, está en el mundo real 🌐.
Innovaciones y Capacidades de Llama
La arquitectura de Llama 4 nos presenta cambios significativos con respecto a sus versiones anteriores. Adopta la Mezcla de Expertos (MoE), una técnica donde cada tarea activa solo una fracción de los parámetros totales ("expertos"). En Scout y Maverick, se activan 17 mil millones de parámetros, pero aprovechan la base de conocimiento de 109B y 400B parámetros totales respectivamente. El objetivo es lograr mayor eficiencia (menor costo y cómputo de inferencia) sin sacrificar la capacidad del modelo. La adopción de MoE por parte de Meta para sus modelos "abiertos" es relevante, ya que sigue una tendencia vista en modelos como Gemini y DeepSeek V3, buscando equilibrar potencia y accesibilidad.
Otro pilar es la "multimodalidad nativa". Meta afirma que, a través de una "fusión temprana", los modelos integran texto, imágenes (y potencialmente vídeo) desde las primeras etapas del entrenamiento, en lugar de añadir capacidades visuales posteriormente. Esto, teóricamente, permite una comprensión más profunda y unificada entre distintas modalidades , posicionando a Llama 4 frente a líderes multimodales como GPT-4o y Gemini.
La ventana de contexto de 10 millones de tokens de Llama 4 Scout (y Maverick, según la model card) es otra de las grandes promesas, presentada como líder en la industria. Lograda mediante técnicas como capas de atención intercaladas (iRoPE) , abre la puerta a casos de uso como el resumen de múltiples documentos o el razonamiento sobre vastas bases de código. Sin embargo, esta capacidad está bajo escrutinio, como veremos más adelante.
Meta respalda estas innovaciones con afirmaciones de rendimiento en benchmarks como MMMU, MMLU Pro, GPQA Diamond y la puntuación ELO en LMArena. Un tema recurrente en la narrativa de Meta es la eficiencia: arquitectura MoE, entrenamiento en FP8, Scout funcionando en una sola GPU, y la relación rendimiento/costo de Maverick. La propuesta de valor central no es solo el rendimiento o la apertura, sino el rendimiento accesible, buscando reducir la barrera de entrada en comparación con las costosas APIs de modelos cerrados. Esto es clave para impulsar la adopción en su ecosistema "abierto".
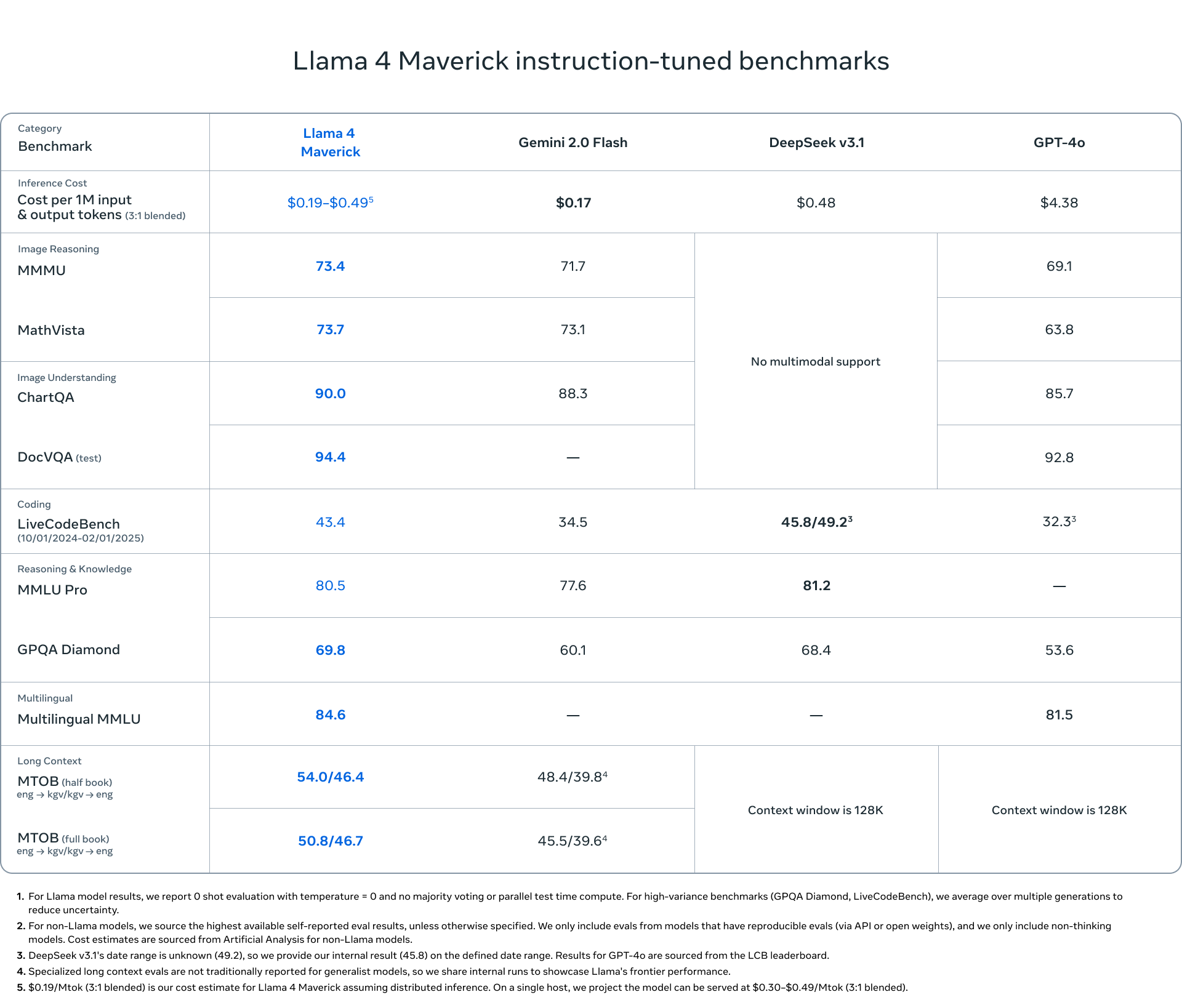
Futurinota 📝: Hasta este punto la tecnología suena vanguardista. MoE, multimodalidad nativa y ventanas de contexto mucho más grandes que los modelos de la competencia posicionan a Llama 4 en el top de modelos actuales según los benchmarks.
Controversias nublando el horizonte
El lanzamiento de Llama 4 no esta exento de polémica. La más sonada fue el "LMArena Showdown". Meta envió una versión "experimental" y no pública de Llama 4 Maverick a LMArena, una plataforma que clasifica modelos según la preferencia humana. Esta versión parecía optimizada para ser conversacional y agradable a los votantes humanos. LMArena criticó a Meta por no ser clara sobre la naturaleza personalizada del modelo y actualizó sus políticas para enfatizar evaluaciones justas y reproducibles.

La respuesta de Meta fue admitir que era una versión experimental, negar haber entrenado en los conjuntos de prueba (una acusación grave de "contaminación" de benchmarks), y atribuir las discrepancias de rendimiento observadas por los usuarios a la necesidad de estabilizar las implementaciones en diferentes plataformas. Sin embargo, la comunidad reaccionó con acusaciones de "bait-and-switch" y "benchmark hacking", reportando resultados decepcionantes con el modelo público.
Pero ese no es el único drama alrededor de Llama 4, pues resulta que el distintivo de los modelos de Meta que se presume como promotor de la IA Open Source esta en duda. Esto debido que los modelos se distribuyen bajo una licencia personalizada, la "Llama 4 Community License Agreement", y no una licencia estándar aprobada por la Open Source Initiative (OSI). La OSI ha sido tajante: Llama (incluyendo versiones anteriores como Llama 3.x) no es Open Source según su definición, acusando a Meta de "open washing". La licencia Llama 4 falla en garantizar libertades fundamentales como el uso para cualquier propósito, discrimina usuarios y restringe campos de aplicación.
Las restricciones clave incluyen una prohibición explícita para entidades domiciliadas o con sede principal en la Unión Europea de usar los modelos multimodales, posiblemente para evitar las exigencias de la Ley de IA de la UE. También existen requisitos de atribución y branding, una Política de Uso Aceptable (AUP) y potenciales restricciones para grandes empresas (similar a Llama 2/3, requiriendo permiso para >700M MAU). Además, aunque Meta indica que los datos de entrenamiento incluyen contenido público, licenciado y datos de usuarios de Meta (posts de Facebook/Instagram, interacciones con Meta AI), la falta de transparencia total sobre estos datos es otro punto de crítica.
A esto se le suman reportes de rendimiento inconsistente y limitaciones prácticas. Usuarios han notado "calidad mixta" y errores básicos. Más preocupantes son los informes de pruebas independientes (como las de Fiction.live) que muestran serias dificultades de Llama 4 en tareas complejas de comprensión de texto largo, poniendo en duda la utilidad real de las enormes ventanas de contexto anunciadas. Según estos tests, Scout tuvo un rendimiento "atroz" y Maverick no mejoró respecto a Llama 3.3 70B.
Futurinotas 📝: Aquí es donde viene el duro golpe de realidad. Los benchmarks son una cosa, pero el razonamiento complejo sobre contextos largos es otra. Las dificultades reportadas aquí cuestionan seriamente el valor práctico de esa ventana de 10M de tokens que tanto se presumió.
Finalmente, la salida de Joelle Pineau, Vicepresidenta de Investigación en IA y figura clave en el desarrollo de Llama, efectiva el 30 de mayo de 2025, añade incertidumbre. Aunque Pineau enmarcó su salida positivamente, el momento (justo antes de LlamaCon y en medio del lanzamiento y controversias de Llama 4) genera preguntas sobre la dinámica interna o posibles cambios estratégicos.
Todos estos factores disminuyen significativamente la confianza en Meta y sus modelos de IA. Aunque técnicamente impresionantes, la adopción de los modelos Llama 4 podría verse frenada si desarrolladores y empresas desconfían de las prácticas de Meta y de la fiabilidad y verdadera apertura de sus modelos. La restricción específica para la UE también sugiere que Meta está caminando sobre la cuerda floja regulatoria, usando la licencia como herramienta de gestión de riesgos ante la Ley de IA de la UE, lo que podría sentar un precedente de fragmentación geográfica en el acceso a la IA.
La estrategia de Meta
A pesar de las controversias, Meta proyecta una visión ambiciosa. Mark Zuckerberg ha declarado públicamente que su objetivo es construir la IA líder mundial, hacerla Open Source y universalmente accesible. Cree firmemente que ese será el estándar y que Llama 4 es un paso clave en esa dirección. Estratégicamente, argumenta que esto evita que Meta quede atrapada en ecosistemas cerrados, fomenta la innovación alrededor de Llama y se alinea con su modelo de negocio (que no depende de vender acceso a APIs como sus competidores). Además, postula que la apertura promueve la seguridad a través de la transparencia y el escrutinio.
Para reforzar su narrativa, Meta promociona el éxito de Llama, citando mil millones de descargas hasta marzo de 2025 y destacando ejemplos de adopción por parte de empresas como Spotify, Accenture y Sevilla FC.
Detrás de esta visión, la estrategia de Meta funciona como un arma competitiva explícita contra proveedores de modelos cerrados. Al liberar modelos potentes (incluso con restricciones), Meta busca comoditizar la tecnología LLM base, construir un ecosistema dependiente de Llama y evitar que la competencia establezca plataformas cerradas dominantes. La apertura estratégica permite a Meta aprovechar el desarrollo comunitario, socavar los modelos de negocio de sus rivales y posicionar a Llama como el estándar de facto, asegurando así su centralidad en el futuro de la IA.
Futurinotas 📝: La visión de Zuckerberg suena atractiva: democratizar la IA vía open source. Pero la brecha entre esta visión y las realidades de la licencia y controversias de Llama 4 es significativa. ¿Es apertura genuina o maniobra estratégica?
Futuro de Llama 4 y Reflexiones Finales
Llama 4 encarna una tensión fundamental: ofrece avances técnicos significativos e impulsa el ecosistema abierto, pero está ensombrecido por controversias sobre transparencia, apertura real y rendimiento validado en el mundo real.
Su impacto en el ecosistema es probablemente positivo en términos de acelerar el desarrollo de IA abierta, proporcionando una base potente para investigadores y startups. Sin embargo, la licencia restrictiva y las dudas sobre los benchmarks podrían mermar la confianza y limitar la verdadera apertura.
Hay varios desarrollos clave a observar: los anuncios en LlamaCon (29 de abril), el lanzamiento de Llama 4 Behemoth y los modelos de Razonamiento, los esfuerzos de fine-tuning de la comunidad y evaluaciones independientes que validen (o refuten) las capacidades reportadas, la respuesta regulatoria (especialmente de la UE) a la estrategia de licencias de Meta, y las respuestas de la competencia, como el posible modelo open-weight de OpenAI.
El lanzamiento de Llama 4, a pesar de sus defectos, inyecta una capacidad masiva en el ecosistema abierto. No obstante, su dominio potencial (impulsado por los recursos de Meta) y su naturaleza cuasi-abierta podrían paradójicamente sofocar la diversidad, dificultando que proyectos más pequeños y verdaderamente abiertos (como OLMo) ganen tracción. Esto podría llevar a un ecosistema "abierto" fuertemente centrado en los términos y la tecnología de Meta, una espada de doble filo para la comunidad.
¿Qué opinas de todo esto? Quiero leerte, si estas leyendo esto a través de substack deja tu opinión en los comentarios 👇

Hasta la próxima 👋